变量和数据类型
python 关键字
下列的标识符是 Python3 的关键字,并且不能用于通常的标识符。关键字必须完全按照下面拼写:
1 | False def if raise |
变量的定义与赋值
在 Python 中 我们不需要为变量指定数据类型。所以你可以直接写出 abc = 1 ,这样变量 abc 就是整数类型。如果你写出 abc = 1.0 ,那么变量 abc 就是浮点类型。
Python 也能操作字符串,它们用单引号或双引号括起来,就像下面这样。
1 | >>> 'ShiYanLou' |
input() 函数
通常情况下,Python 的代码中是不需要从键盘读取输入的。不过我们还是可以在 Python 中使用函数 input() 来做到这一点,input() 有一个用于打印在屏幕上的可选字符串参数,返回用户输入的字符串
1 | #!/usr/bin/env python3 |
字符串的格式化
1 | >>>"{} {}".format("hello", "world") # 不设置指定位置,按默认顺序 |
| 3.1415926 | {:.2f} | 3.14 | 保留小数点后两位 |
|---|---|---|---|
| 3.1415926 | {:+.2f} | +3.14 | 带符号保留小数点后两位 |
| -1 | {:+.2f} | -1.00 | 带符号保留小数点后两位 |
| 2.71828 | {:.0f} | 3 | 不带小数 |
| 5 | {:0>2d} | 05 | 数字补零 (填充左边, 宽度为2) |
| 5 | {:x<4d} | 5xxx | 数字补x (填充右边, 宽度为4) |
| 10 | {:x<4d} | 10xx | 数字补x (填充右边, 宽度为4) |
| 1000000 | {:,} | 1,000,000 | 以逗号分隔的数字格式 |
| 0.25 | {:.2%} | 25.00% | 百分比格式 |
| 1000000000 | {:.2e} | 1.00e+09 | 指数记法 |
| 13 | {:>10d} | 13 | 右对齐 (默认, 宽度为10) |
| 13 | {:<10d} | 13 | 左对齐 (宽度为10) |
| 13 | {:^10d} | 13 | 中间对齐 (宽度为10) |
| 11 | '{:b}'.format(11) '{:d}'.format(11) '{:o}'.format(11) '{:x}'.format(11) '{:#x}'.format(11) '{:#X}'.format(11) |
1011 11 13 b 0xb 0XB |
进制 |
^, <**, **> 分别是居中、左对齐、右对齐,后面带宽度, : 号后面带填充的字符,只能是一个字符,不指定则默认是用空格填充。
+ 表示在正数前显示 **+**,负数前显示 **-**; (空格)表示在正数前加空格
b、d、o、x 分别是二进制、十进制、八进制、十六进制。
此外我们可以使用大括号 {} 来转义大括号,如下实例:
print ("{} 对应的位置是 {{0}}".format("runoob"))
单行定义多变量并赋值
你甚至可以在一行内将多个值赋值给多个变量(元组封装和拆封)。
要明白这是怎么工作的,你需要学习元组(tuple)这个数据类型。我们是用逗号创建元组。在赋值语句的右边我们创建了一个元组,我们称这为元组封装(tuple packing),赋值语句的左边我们则做的是元组拆封 (tuple unpacking)。
1 | a , b = 45, 54 |
这个技巧用来交换两个数的值非常方便。
1 | >>> a, b = b , a |
运算符和表达式
/ :除法
// : 整除
关系、逻辑运算
对于逻辑 与,或,非,我们使用 and,or,not 这几个关键字
逻辑运算符的优先级又低于关系运算符,在它们之中,not 具有最高的优先级,or 优先级最低,所以 A and not B or C 等于 (A and (notB)) or C
表达式
简写运算符:
x op= expression 为简写运算的语法形式。其等价于 x = x op expression
1 | >>> a = 12 |
类型转换
我们可以手动的执行类型转换。
| 类型转换函数 | 转换路径 |
|---|---|
float(string) |
字符串 -> 浮点值 |
int(string) |
字符串 -> 整数值 |
str(integer) |
整数值 -> 字符串 |
str(float) |
浮点值 -> 字符串 |
序列(列表)操作
列表的数据结构。它可以写作中括号之间的一列逗号分隔的值。列表的元素不必是同一类型:
1 | >>> a = [ 1, 342, 223, 'India', 'Fedora'] |
负数的索引,那将会从列表的末尾-1开始计数
正数的索引,那将会从列表的开头0开始计数
1 | +---+-----+-----+---------+----------+ |
试图使用太大的索引会导致错误:
1 | >>> a[32] |
切片
甚至可以把它切成不同的部分,这个操作称为切片,例子在下面给出:
1 | >>> a = [ 1, 342, 223, 'India', 'Fedora'] |
切片并不会改变正在操作的列表,切片操作返回其子列表,这意味着下面的切片操作返回列表一个新的(栈)拷贝副本
切片的索引有非常有用的默认值;省略的第一个索引默认为零,省略的第二个索引默认为切片的字符串的大小
Python 中有关下标的集合都满足左闭右开原则,切片中也是如此,也就是说集合左边界值能取到,右边界值不能取到。
Python 能够优雅地处理那些没有意义的切片索引:一个过大的索引值(即大于列表实际长度)将被列表实际长度所代替,当上边界比下边界大时(即切片左值大于右值)就返回空列表:
1 | >>> a[2:32] |
切片步长
切片操作还可以设置步长,就像下面这样:
1 | >>> a[1::2] |
它的意思是,从切片索引 1 到列表末尾,每隔两个元素取值。
列表拼接
列表也支持连接这样的操作,它返回一个新的列表:
1 | >>> a + [36, 49, 64, 81, 100] |
列表赋值
也可以对切片赋值,此操作可以改变列表的尺寸,或清空它:
1 | >>> letters = ['a', 'b', 'c', 'd', 'e', 'f', 'g'] |
细心的同学可能发问了,前面不是说过切片操作不改变列表么?严格来说,这里并不算真正的切片操作,只是上面代码中赋值运算符左边的这种操作与切片操作形式一样而已。



三、列表
在继续学习循环之前,我们先学习一个叫做列表的数据结构。它可以写作中括号之间的一列逗号分隔的值。列表的元素不必是同一类型:
1 | >>> a = [ 1, 342, 223, 'India', 'Fedora'] |
你可以将上面的列表想象为一堆有序的盒子,盒子包含有上面提到的值,每个盒子都有自己的编号(红色的数字),编号从零开始,你可以通过编号访问每一个盒子里面的值。对于列表,这里的编号称为索引。

我们像下面这样通过索引来访问列表中的每一个值:
1 | >>> a[0] |
如果我们使用负数的索引,那将会从列表的末尾开始计数,像下面这样:
1 | >>> a[-1] |
你甚至可以把它切成不同的部分,这个操作称为切片,例子在下面给出:
1 | >>> a[0:-1] |
切片并不会改变正在操作的列表,切片操作返回其子列表,这意味着下面的切片操作返回列表一个新的(栈)拷贝副本:
1 | >>> a[:] |
切片的索引有非常有用的默认值;省略的第一个索引默认为零,省略的第二个索引默认为切片的字符串的大小:
1 | >>> a[:-2] |
有个办法可以很容易地记住切片的工作方式:切片时的索引是在两个元素之间 。左边第一个元素的索引为 0,而长度为 n 的列表其最后一个元素的右界索引为 n。例如:
1 | +---+-----+-----+---------+----------+ |
上面的第一行数字给出列表中的索引点 0…5。第二行给出相应的负索引。切片是从 i 到 j 两个数值表示的边界之间的所有元素。
对于非负索引,如果上下都在边界内,切片长度就是两个索引之差。例如 a[2:4] 是 2。
Python 中有关下标的集合都满足左闭右开原则,切片中也是如此,也就是说集合左边界值能取到,右边界值不能取到。
对上面的列表, a[0:5] 用数学表达式可以写为 [0,5) ,其索引取值为 0,1,2,3,4,所以能将a中所有值获取到。 你也可以用a[:5], 效果是一样的。
而a[-5:-1],因为左闭右开原则,其取值为 -5,-4,-3,-2 是不包含 -1 的。
为了取到最后一个值,你可以使用 a[-5:] ,它代表了取该列表最后5个值。
试图使用太大的索引会导致错误:
1 | >>> a[32] |
Python 能够优雅地处理那些没有意义的切片索引:一个过大的索引值(即大于列表实际长度)将被列表实际长度所代替,当上边界比下边界大时(即切片左值大于右值)就返回空列表:
1 | >>> a[2:32] |
切片操作还可以设置步长,就像下面这样:
1 | >>> a[1::2] |
它的意思是,从切片索引 1 到列表末尾,每隔两个元素取值。
列表也支持连接这样的操作,它返回一个新的列表:
1 | >>> a + [36, 49, 64, 81, 100] |
列表允许修改元素:
1 | >>> cubes = [1, 8, 27, 65, 125] |
也可以对切片赋值,此操作可以改变列表的尺寸,或清空它:
1 | >>> letters = ['a', 'b', 'c', 'd', 'e', 'f', 'g'] |
细心的同学可能发问了,前面不是说过切片操作不改变列表么?严格来说,这里并不算真正的切片操作,只是上面代码中赋值运算符左边的这种操作与切片操作形式一样而已。
元素包含
要检查某个值是否存在于列表中,你可以这样做:
1 | >>> a = ['ShiYanLou', 'is', 'cool'] |
控制流和循环
1 | if expression: |
while 语句的语法如下:
1 | while condition: |
关键字 break,它可以终止最里面的循环
for 循环遍历任何序列(比如列表和字符串)中的每一个元素。下面给出示例:
1 | a = ['ShiYanLou', 'is', 'powerful'] |
我们也能这样做:
1 | >>> a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] |
range() 函数
如果你需要一个数值序列,内置函数 range() 会很方便,它生成一个等差数列(并不是列表):
1 | range(1, 5) |
循环的else 语句
我们可以再循环后面使用可选的
else,它将再循环执行完毕后执行,除非有break语句终止了循环python 中
for循环的else子句给我们提供了检测循环是否顺利执行完毕的一种优雅方法。
数据结构
列表
append() : 添加元素 到列表末尾insert(): 将数据插入到列表的指定位置count(): 元素在列表中出现了多少次remove(): 在列表中移除任意指定值reverse(): 反转整个列表extend(): 将一个列表的所有元素添加到另一个列表的末尾sort(): 列表排序, 前提是列表的元素是可比较的del关键字:删除指定位置的列表元素
将列表用作栈和队列
栈: 一种 LIFO (Last In First Out 后进先出)数据结构
1 | a = [1, 2, 3, 4, 5, 6] |
上面的代码中我们使用了一个新方法 pop()。传入一个参数 i 即 pop(i) 会将第 i 个元素弹出。
队列: 它是 FIFO (First In First Out 先进先出)的数据结构
1 | a = [1, 2, 3, 4, 5] |
我们使用 a.pop(0) 弹出列表中第一个元素。
列表推导式
列表推导式由包含一个表达式的中括号组成,表达式后面跟随一个 for 子句,之后可以有零或多个 for 或 if 子句。结果是一个列表,由表达式依据其后面的 for 和 if 子句上下文计算而来的结果构成。
1 | squares = [x**2 for x in range(10)] |
元组
- 元组是由数个逗号分割的值组成
- 可以对任何一个元组执行拆封操作并赋值给多个变量
- 元组是不可变类型,这意味着你不能在元组内删除或添加或编辑任何值
- 要创建只含有一个元素的元组,在值后面跟一个逗号
集合
集合是一个无序不重复元素的集。基本功能包括关系测试和消除重复元素。集合对象还支持 union(联合),intersection(交),difference(差)和 symmetric difference(对称差集)等数学运算。
大括号或 set() 函数可以用来创建集合。注意:想要创建空集合,你必须使用 set() 而不是 {}。后者用于创建空字典
1 | # 演示对两个单词中的字母进行集合操作 |
从集合中添加或弹出元素:
1 | a = {'a','e','h','g'} |
字典
字典是是无序的键值对(
key:value)集合,同一个字典内的键必须是互不相同的。一对大括号{}创建一个空字典。初始化字典时,在大括号内放置一组逗号分隔的键:值对,这也是字典输出的方式。我们使用键来检索存储在字典中的数据。
1 | data = {'kushal':'Fedora', 'kart_':'Debian', 'Jace':'Mac'} |
创建新的键值对很简单:
1 | data['parthan'] = 'Ubuntu' |
使用 del 关键字删除任意指定的键值对:
1 | del data['kushal'] |
使用 in 关键字查询指定的键是否存在于字典中。
1 | 'ShiYanLou' in data |
字典中的键必须是不可变类型,比如你不能使用列表作为键!!!
dict() 可以从包含键值对的元组中创建字典。
1 | dict((('Indian','Delhi'),('Bangladesh','Dhaka'))) |
如果你想要遍历一个字典,使用字典的 items() 方法。
1 | data |
许多时候我们需要往字典中的元素添加数据,我们首先要判断这个元素是否存在,不存在则创建一个默认值。如果在循环里执行这个操作,每次迭代都需要判断一次,降低程序性能。
我们可以使用 dict.setdefault(key, default) 更有效率的完成这个事情。
return: 如果字典中包含有给定键,则返回该键对应的值,否则返回为该键设置的值。
1 | data = {} |
试图索引一个不存在的键将会抛出一个 keyError 错误。我们可以使用 dict.get(key, default) 来索引键,如果键不存在,那么返回指定的 default 值。
1 | data['foo'] |
enumerate()
如果你想要在遍历列表(或任何序列类型)的同时获得元素索引值,你可以使用 enumerate()。
1 | for i, j in enumerate(['a', 'b', 'c']): |
zip()
你也许需要同时遍历两个序列类型,你可以使用 zip() 函数。
1 | a = ['Pradeepto', 'Kushal'] |
字符串
split(): split() 分割任意字符串,允许有一个参数,用来指定字符串以什么字符分隔(默认为 " "),它返回一个包含所有分割后的字符串的列表join(): 方法 join() 使用指定字符连接多个字符串,它需要一个包含字符串元素的列表作为输入然后连接列表内的字符串元素title():upper():swapcase():
isalnum() :
isalpha() :
1 | s = "We all love Python" |
字符串剥离
字符串有几个进行剥离操作的方法。最简单的一个是 strip(chars),用来剥离字符串首尾中指定的字符,它允许有一个字符串参数,这个参数为剥离哪些字符提供依据。不指定参数则默认剥离掉首尾的空格和换行符,代码如下:
1 | s = " a bc\n " |
你可以使用 lstrip(chars) 或 rstrip(chars) 只对字符串左或右剥离。
1 | s = "www.foss.in" |
文本搜索
1 | s = "faulty for a reason" |
回文检查
1 | s = input("Please enter a string: ") |
函数
局域或全局变量
1 | a = 9 |
使用 global 关键字,对函数中的 a 标志为全局变量,让函数内部使用全局变量的 a,那么整个程序中出现的 a 都将是这个:
1 | #!/usr/bin/env python3 |
关键字 global 来告诉 a 的定义是全局的,因此在函数内部更改了 a 的值,函数外 a 的值也实际上更改了
默认参数值
第一个是具有默认值的参数后面不能再有普通参数,比如
f(a,b=90,c)就是错误的是默认值只被赋值一次,因此如果默认值是任何可变对象时会有所不同,比如列表、字典或大多数类的实例。例如,下面的函数在后续调用过程中会累积(前面)传给它的参数
1
2
3
4
5
6
7
8
9
10def f(a, data=[]):
data.append(a)
return data
...
print(f(1))
[1]
print(f(2))
[1, 2]
print(f(3))
[1, 2, 3]要避免这个问题,你可以像下面这样:
1
2
3
4
5
6
7
8
9
10def f(a, data=None):
if data is None:
data = []
data.append(a)
return data
...
print(f(1))
[1]
print(f(2))
[2]
关键字参数
函数可以通过关键字参数的形式来调用,形如 keyword = value。如下:
1 | def func(a, b=5, c=10): |
在上面的例子中你能看见调用函数时使用了变量名,比如 func(12,c = 24),这样我们将 24 赋给 c 且 b 具有默认值。
强制关键字参数
我们也能将函数的参数标记为只允许使用关键字参数。用户调用函数时将只能对每一个参数使用相应的关键字参数。(* 号后面只能使用强制关键字)
1 | def hello(*, name='User'): |
高阶函数
高阶函数(Higher-order function)或仿函数(functor)是可以接受函数作为参数的函数:
- 使用一个或多个函数作为参数
- 返回另一个函数作为输出
Python 里的任何函数都可以作为高阶函数,下面举一个简单的例子:
1 | # 创建一个函数,将参数列表中每个元素都变成全大写 |
map函数
map 是一个在 Python 里非常有用的高阶函数。它接受一个函数和一个序列(迭代器)作为输入,然后对序列(迭代器)的每一个值应用这个函数,返回一个序列(迭代器),其包含应用函数后的结果。
1 | lst = [1, 2, 3, 4, 5] |
在 Python 中还有其它的高阶函数,如 sorted()、filter() 以及 functools 模块中的函数
filter()函数: filter()把传入的函数依次作用于每个元素,然后根据返回值是True还是False决定保留还是丢弃该元素。
1 | def is_odd(n): |
sorted()函数:
1 | sorted([36, 5, -12, 9, -21]) |
文件处理
文件打开
open() 函数打开文件。它需要两个参数,第一个参数是文件路径或文件名,第二个是文件的打开模式。模式通常是下面这样的:
"r",以只读模式打开,你只能读取文件但不能编辑/删除文件的任何内容"w",以写入模式打开,如果文件存在将会删除里面的所有内容,然后打开这个文件进行写入"a",以追加模式打开,写入到文件中的任何数据将自动添加到末尾
默认的模式为只读模式,也就是说如果你不提供任何模式,open() 函数将会以只读模式打开文件
文件关闭
close() 完成这个操作。
1 | fobj.close() |
始终确保你显式关闭每个打开的文件,一旦它的工作完成你没有任何理由保持打开文件。因为程序能打开的文件数量是有上限的。如果你超出了这个限制,没有任何可靠的方法恢复,因此程序可能会崩溃。每个打开的文件关联的数据结构(文件描述符/句柄/文件锁…)都要消耗一些主存资源。因此如果许多打开的文件没用了你可以结束大量的内存浪费,并且文件打开时始终存在数据损坏或丢失的可能性。
文件读取
read()方法一次性读取整个文件read(size)有一个可选的参数size,用于指定字符串长度。如果没有指定size或者指定为负数,就会读取并返回整个文件。当文件大小为当前机器内存两倍时,就会产生问题。反之,会尽可能按比较大的 size 读取和返回数据。readline()能帮助你每次读取文件的一行。readlines()方法读取所有行到一个列表中
使用 with 语句
实际情况中,我们应该尝试使用 with 语句处理文件对象,它会在文件用完后会自动关闭,就算发生异常也没关系。它是 try-finally 块的简写:
1 | with open('sample.txt') as fobj: |
异常
try...except 块来处理任意异常。基本的语法像这样:
1 | try: |
它以如下方式工作:
如果没有异常发生,
except子句 在try语句执行完毕后就被忽略了。如果在
try子句执行过程中发生了异常,那么该子句其余的部分就会被忽略。如果异常匹配于
except关键字后面指定的异常类型,就执行对应的except子句。然后继续执行try语句之后的代码。如果发生了一个异常,在
except子句中没有与之匹配的分支,它就会传递到上一级try语句中。如果最终仍找不到对应的处理语句,它就成为一个 未处理异常,终止程序运行,显示提示信息。
抛出异常raise
使用raise语句抛出一个异常
使用 raise 语句抛出一个异常。
1 | raise ValueError("A value error happened.") |
我们可以捕获任何其它普通异常一样,来捕获这些异常。
1 | try: |
定义清理行为finally
try 语句还有另一个可选的 finally 子句,目的在于定义在任何情况下都一定要执行的功能。例如:
1 | >>> try: |
不管有没有发生异常,finally 子句 在程序离开 try 后都一定会被执行。当 try 语句中发生了未被 except 捕获的异常(或者它发生在 except 或 else 子句中),在 finally 子句执行完后它会被重新抛出。
在真实场景的应用程序中,finally 子句用于释放外部资源(文件或网络连接之类的),无论它们的使用过程中是否出错。
with 语句,它是 try-finally 块的简写,使用 with 语句能保证文件始终被关闭。
类
__init__ 方法
类定义了 __init__() 方法的话,类的实例化操作会自动为新创建的类实例调用 __init__() 方法 继承
继承
当一个类继承另一个类时,它将继承父类的所有功能(如变量和方法)。这有助于重用代码。
在下一个例子中我们首先创建一个叫做 Person 的类,然后创建两个派生类 Student 和 Teacher。当两个类都从 Person 类继承时,它们的类除了会有 Person 类的所有方法还会有自身用途的新方法和新变量。
多继承
一个类可以继承自多个类,具有父类的所有变量和方法,语法如下:
1 | class MyClass(Parentclass1, Parentclass2,...): |
删除对象
现在我们已经知道怎样创建对象,现在我们来看看怎样删除一个对象。我们使用关键字 del 来做到这个。
1 | >>> s = "I love you" |
del 实际上使对象的引用计数减少一,当对象的引用计数变成零的时候,垃圾回收器会删除这个对象
属性(attributes)读取方法
在 Python 里请不要使用属性(attributes\)读取方法(*getters* 和 setters)。如果你之前学过其它语言(比如 Java),你可能会想要在你的类里面定义属性读取方法。请不要这样做,直接使用属性就可以了,就像下面这样:
1 | class Student(object): |
装饰器
你可能想要更精确的调整控制属性访问权限,你可以使用 @property 装饰器,@property 装饰器就是负责把一个方法变成属性调用的。
下面有个银行账号的例子,我们要确保没人能设置金额为负,并且有个只读属性 cny 返回换算人民币后的金额。
1 | class Account(object): |
模块
到目前为止,我们在 Python 解释器中写的所有代码都在我们退出解释器的时候丢失了。但是当人们编写大型程序的时候他们会倾向于将代码分为多个不同的文件以便使用,调试以及拥有更好的可读性。在 Python 中我们使用模块来到达这些目的。模块是包括 Python 定义和声明的文件。文件名就是模块名加上
.py后缀。
你可以由全局变量 __name__ 得到模块的模块名(一个字符串)。
1 | import <module> |
包
含有 __init__.py 文件的目录可以用来作为一个包,目录里的所有 .py 文件都是这个包的子模块。
如果 __init__.py 文件内有一个名为 __all__ 的列表,那么只有在列表内列出的名字将会被公开
if __name__ == '__main__': 这条语句,它的作用是,只有在当前模块名为 __main__ 的时候(即作为脚本执行的时候)才会执行此 if 块内的语句。换句话说,当此文件以模块的形式导入到其它文件中时,if 块内的语句并不会执行。
Collections模块
Counter 类
Counter 示例
1 | >>> from collections import Counter |
Counter 对象有一个叫做 elements() 的方法,其返回的序列中,依照计数重复元素相同次数,元素顺序是无序的。
1 | >>> c = Counter(a=4, b=2, c=0, d=-2) |
most_common() 方法返回最常见的元素及其计数,顺序为最常见到最少。
1 | >>> Counter('abracadabra').most_common(3) |
defaultdict 类
defaultdict 是内建 dict 类的子类,它覆写了一个方法并添加了一个可写的实例变量。其余功能与字典相同。
defaultdict() 第一个参数提供了 default_factory 属性的初始值,默认值为 None,default_factory 属性值将作为字典的默认数据类型。所有剩余的参数与字典的构造方法相同,包括关键字参数。
同样的功能使用 defaultdict 比使用 dict.setdefault 方法快。
defaultdict 用例
1 | >>> from collections import defaultdict |
在例子中你可以看到,即使 defaultdict 对象不存在某个键,它会自动创建一个空列表。
namedtuple 类
命名元组有助于对元组每个位置赋予意义,并且让我们的代码有更好的可读性和自文档性。你可以在任何使用元组地方使用命名元组。在例子中我们会创建一个命名元组以展示为元组每个位置保存信息。
1 | >>> from collections import namedtuple |
PEP8 代码风格指南
代码排版
续行
续行要么与圆括号、中括号、花括号这样的被包裹元素保持垂直对齐,要么放在 Python 的隐线(注:应该是相对于def的内部块)内部,或者使用悬挂缩进。使用悬挂缩进的注意事项:第一行不能有参数,用进一步的缩进来把其他行区分开。
1 | # Aligned with opening delimiter. |
当 if 语句的条件部分足够长,需要将它写入到多个行,值得注意的是两个连在一起的关键字(i.e. if),添加一个空格,给后续的多行条件添加一个左括号形成自然地4空格缩进。如果和嵌套在 if 语句内的缩进代码块产生了视觉冲突,也应该被自然缩进4个空格。这份增强建议书对于怎样(或是否)把条件行和 if 语句的缩进块在视觉上区分开来是没有明确规定的。可接受的情况包括,但不限于:
1 | # No extra indentation. |
在多行结构中的右圆括号、右中括号、右大括号应该放在最后一行的第一个非空白字符的正下方,如下所示:
1 | my_list = [ |
或者放在多行结构的起始行的第一个字符正下方,如下:
1 | my_list = [ |
每行最大长度
限制每行的最大长度为79个字符。
Python 标准库是非常专业的,限制最大代码长度为79个字符(注释和文档字符串最大长度为72个字符)。
首选的换行方式是在括号(小中大)内隐式换行(非续行符\)。长行应该在括号表达式的包裹下换行。这比反斜杠作为续行符更好。
反斜杠有时仍然适用。例如,多个很长的with语句不能使用隐式续行,因此反斜杠是可接受的。
1 | with open('/path/to/some/file/you/want/to/read') as file_1, \ |
遇到二元操作符,首选的断行位置是操作符的后面而不是前面。这有一些例子:
1 | class Rectangle(Blob): |
迭代器、生成器、装饰器
迭代器
Python 迭代器(Iterators)对象在遵守迭代器协议时需要支持如下两种方法。
__iter__(),返回迭代器对象自身。这用在for in语句中。__next__(),返回迭代器的下一个值。如果没有下一个值可以返回,那么应该抛出StopIteration异常。
1 | class Counter(object): |
现在我们能把这个迭代器用在我们的代码里。
1 | c = Counter(5,10) |
请记住迭代器只能被使用一次。这意味着迭代器一旦抛出 StopIteration,它会持续抛出相同的异常。
1 | c = Counter(5,6) |
我们已经看过在 for 循环中使用迭代器的例子了,下面的例子试图展示迭代器被隐藏的细节:
1 | iterator = iter(c) |
生成器
Python 生成器(Generators)是更简单的创建迭代器的方法,这通过在函数中使用 yield 关键字完成:
1 | def my_generator(): |
在上面的例子中我们使用 yield 语句创建了一个简单的生成器。我们能在 for 循环中使用它,就像我们使用任何其它迭代器一样。
1 | for char in my_generator(): |
在下一个例子里,我们会使用一个生成器函数完成与 Counter 类相同的功能,并且把它用在 for 循环中。
1 | >>> def counter_generator(low, high): |
在 While 循环中,每当执行到 yield 语句时,返回变量 low 的值并且生成器状态转为挂起。在下一次调用生成器时,生成器从之前冻结的地方恢复执行然后变量 low 的值增一。生成器继续 while 循环并且再次来到 yield 语句…
当你调用生成器函数时它返回一个生成器对象。如果你把这个对象传入 dir() 函数,你会在返回的结果中找到 __iter__ 和 __next__ 两个方法名。
1 | c = counter_generator(5, 10) |
我们通常使用生成器进行惰性求值。这样使用生成器是处理大数据的好方法。如果你不想在内存中加载所有数据,你可以使用生成器,一次只传递给你一部分数据。
我们可以使用生成器产生无限多的值。以下是一个这样的例子。
1 | >>> def infinite_generator(start=0): |
如果我们回到 my_generator() 这个例子,我们会发现生成器的一个特点:它们是不可重复使用的。
1 | >>> g = my_generator() |
一个创建可重复使用生成器的方式是不保存任何状态的基于对象的生成器。任何一个生成数据的含有 __iter__ 方法的类都可以用作对象生成器。在下面的例子中我们重新创建了 counter 生成器。
1 | >>> class Counter(object): |
上面的 gobj 并不是生成器或迭代器,因为它不具有 __next__ 方法,只是一个可迭代对象,生成器是一定不能重复循环的。
如果想要使类的实例变成迭代器,可以用 __iter__ + __next__ 方法实现:
1 | >>> from collections import Iterator |
生成器表达式
生成器表达式(Generator expressions)是列表推导式和生成器的一个高性能,内存使用效率高的推广。
举个例子,我们尝试对 1 到 9 的所有数字进行平方求和。
1 | sum([x*x for x in range(1,10)]) |
这个例子实际上首先在内存中创建了一个平方数值的列表,然后遍历这个列表,最终求和后释放内存。你能理解一个大列表的内存占用情况是怎样的。
我们可以通过使用生成器表达式来节省内存使用。
1 | sum(x*x for x in range(1,10)) |
生成器表达式的语法要求其总是直接在在一对括号内,并且不能在两边有逗号。这基本上意味着下面这些例子都是有效的生成器表达式用法示例:
1 | sum(x*x for x in range(1,10)) |
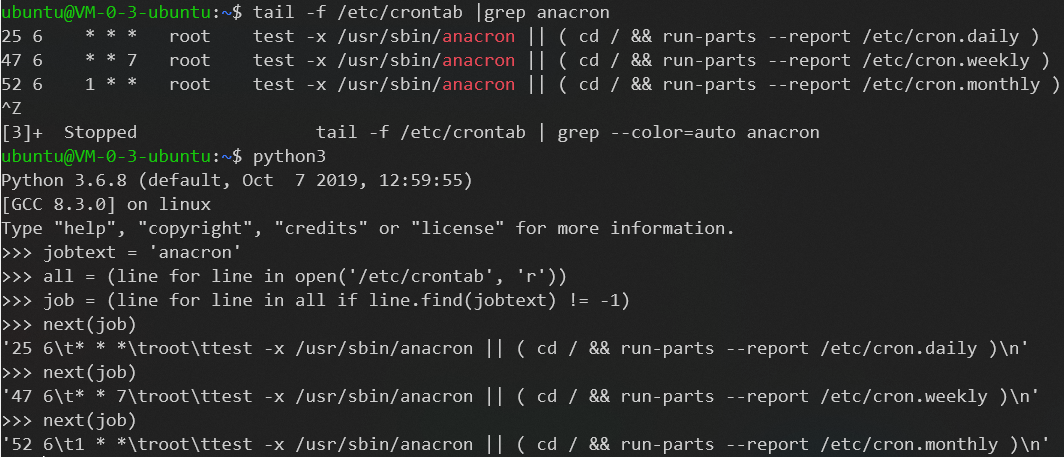
我们可以把生成器和生成器表达式联系起来,在下面的例子中我们会读取文件 '/var/log/cron' 并且查看任意指定任务(例中我们搜索 'anacron' )是否成功运行。
我们可以用 shell 命令 tail -f /etc/crontab |grep anacron 完成同样的事(按 Ctrl + C 终止命令执行)。
闭包
闭包(Closures)是由另外一个函数返回的函数。我们使用闭包去除重复代码。在下面的例子中我们创建了一个简单的闭包来对数字求和。
1 | >>> def add_number(num): |
adder 是一个闭包,把一个给定的数字与预定义的一个数字相加。
装饰器
装饰器(Decorators)用来给一些对象动态的添加一些新的行为,我们使用过的闭包也是这样的。
我们会创建一个简单的示例,将在函数执行前后打印一些语句。
1 | def my_decorator(func): |
Virtualenv
虚拟的 Python 环境(简称 venv) 是一个能帮助你在本地目录安装不同版本的 Python 模块的 Python 环境,你可以不再需要在你系统中安装所有东西就能开发并测试你的代码。
首先安装 pip3,打开 xfce 终端输入下面的命令:
1 | $ sudo apt-get update |
用如下命令安装 virtualenv:
1 | $ sudo pip3 install virtualenv |
我们会创建一个叫做 virtual 的目录,在里面我们会有两个不同的虚拟环境。
1 | $ cd /home/shiyanlou |
下面的命令创建一个叫做 virt1 的环境。
1 | $ cd virtual |
现在我们激活这个 virt1 环境。
1 | $ source virt1/bin/activate |
提示符的第一部分是当前虚拟环境的名字,当你有多个环境的时候它会帮助你识别你在哪个环境里面。
现在我们将安装 redis 这个 Python 模块。
1 | (virt1)$ sudo pip3 install redis |
使用 deactivate 命令关闭虚拟环境。
1 | (virt1)$ deactivate |
现在我们将创建另一个虚拟环境 virt2,我们会在里面同样安装 redis 模块,但版本是 2.8 的旧版本。
1 | $ virtualenv virt2 |
测试
在计算机编程中,单元测试(英语:Unit Testing)又称为模块测试, 是针对程序模块(软件设计的最小单位)来进行正确性检验的测试工作。程序单元是应用的最小可测试部件。在过程化编程中,一个单元就是单个程序、函数、过程等;对于面向对象编程,最小单元就是方法,包括基类(超类)、抽象类、或者派生类(子类)中的方法。
单元测试模块
在 Python 里我们有 unittest 这个模块来帮助我们进行单元测试。
阶乘计算程序:在这个例子中我们将写一个计算阶乘的程序
1 | import sys |
正如你所看到的, fact(n) 这个函数执行所有的计算,所以我们至少应该测试这个函数。
1 | import unittest |
运行测试:
1 | $ python3 factorial_test.py |
说明
我们首先导入了 unittest 模块,然后测试我们需要测试的函数。
测试用例是通过子类化 unittest.TestCase 创建的。
各类 assert 语句
| Method | Checks that | New in |
|---|---|---|
| assertEqual(a, b) | a == b |
|
| assertNotEqual(a, b) | a != b |
|
| assertTrue(x) | bool(x) is True |
|
| assertFalse(x) | bool(x) is False |
|
| assertIs(a, b) | a is b |
2.7 |
| assertIsNot(a, b) | a is not b |
2.7 |
| assertIsNone(x) | x is None |
2.7 |
| assertIsNotNone(x) | x is not None |
2.7 |
| assertIn(a, b) | a in b |
2.7 |
| assertNotIn(a, b) | a not in b |
2.7 |
| assertIsInstance(a, b) | isinstance(a, b) |
2.7 |
| assertNotIsInstance(a, b) | not isinstance(a, b) |
2.7 |